HashMap
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。
既然要介绍HashMap,那么就顺带介绍HashTable,两者进行比对。HashMap和Hashtable都是Map接口的经典实现类,它们之间的关系完全类似于之前介绍的ArrayList和Vector的关系。由于Hashtable是个古老的Map实现类(从Hashtable的命名规范就可以看出,t没有大写,并不是我写错了),需要方法比较繁琐,不符合Map接口的规范。但是Hashtable也具有HashMap不具有的优点。下面我们进行两者之间的比对。
HashMap与Hashtable的区别
(具体见HashMap 和 HashTable 以及 CurrentHashMap 的区别)
1、Hashtable是一个线程安全的Map实现,但HashMap是线程不安全的实现,所以HashMap比Hashtable的性能好一些;但如果有多个线程访问同一个Map对象时,是盗用Hashtable实现类会更好。
2、Hashtable不允许使用null作为key和value,如果试图把null值放进Hashtable中,将会引发NullPointerException异常;但是HashMap可以使用null作为key或value。
HashMap判断key与value相等的标准
key判断相等的标准
类似于HashSet,HashMap与Hashtable判断两个key相等的标准是:
两个key通过equals()方法比较返回true,
两个key的hashCode值也相等,则认为两个key是相等的。
注意:用作key的对象必须实现了hashCode()方法和equals()方法。并且最好两者返回的结果一致,即如果equals()返回true,hashCode()值相等。可参考Set关于这方面的介绍。
value判断相等的标准
HashMap与Hashtable判断两个value相等的标准是:
只要两个对象通过equals()方法比较返回true即可。
注意:HashMap中key所组成的集合元素不能重复,value所组成的集合元素可以重复。
下面程序示范了HashMap判断key与value相等的标准。
public class A {
public int count;
public A(int count) {
this.count = count;
}
//根据count值来计算hashCode值
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + count;
return result;
}
//根据count值来判断两个对象是否相等
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
A other = (A) obj;
if (count != other.count)
return false;
return true;
}
}
public class B {
public int count;
public B(int count) {
this.count = count;
}
//根据count值来判断两个对象是否相等
@Override
public boolean equals(Object obj) {
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
B other = (B) obj;
if (count != other.count)
return false;
return true;
}
}
public class HashMapTest {
public static void main(String[] args){
HashMap map = new HashMap();
map.put(new A(1000), "集合Set");
map.put(new A(2000), "集合List");
map.put(new A(3000), new B(1000));
//仅仅equals()比较为true,但认为是相同的value
boolean isContainValue = map.containsValue(new B(1000));
System.out.println(isContainValue);
//虽然是不同的对象,但是equals()和hashCode()返回结果都相等
boolean isContainKey = map.containsKey(new A(1000));
System.out.println(isContainKey);
//equals()和hashCode()返回结果不满足key相等的条件
System.out.println(map.containsKey(new A(4000)));
}
}
输出结果:
true
true
false
注意:如果是加入HashMap的key是个可变对象,在加入到集合后又修改key的成员变量的值,可能导致hashCode()值以及equal()的比较结果发生变化,无法访问到该key。一般情况下不要修改。
HashMap的本质
下面我们从源码角度来理解HashMap。
HashMap的构造函数
// 默认构造函数。
HashMap()
// 指定“容量大小”的构造函数
HashMap(int capacity)
// 指定“容量大小”和“加载因子”的构造函数
HashMap(int capacity, float loadFactor)
// 包含“子Map”的构造函数
HashMap(Map<? extends K, ? extends V> map)
从构造函数中,了解到两个重要的元素:容量大小(capacity)以及加载因子(loadFactor)。
容量(capacity)是哈希表的容量,初始容量是哈希表在创建时的容量(即DEFAULT_INITIAL_CAPACITY = 1 « 4)。
加载因子 是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 resize操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
通常,默认加载因子是 0.75(即DEFAULT_LOAD_FACTOR = 0.75f), 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本(在大多数 HashMap 类的操作中,包括 get 和 put 操作,都反映了这一点)。在设置容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少 resize操作次数。如果容量大于最大条目数除以加载因子,则不会发生 rehash 操作。
Node类型
HashMap是通过”拉链法”实现的哈希表。它包括几个重要的成员变量:table, size, threshold, loadFactor。
table是一个Node[]数组类型,而Node实际上就是一个单向链表。哈希表的”key-value键值对”都是存储在Node数组中的。
size是HashMap的大小,它是HashMap保存的键值对的数量。
threshold是HashMap的阈值,用于判断是否需要调整HashMap的容量。threshold的值=”容量*加载因子”,当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。
loadFactor就是加载因子。
要想理解HashMap,首先就要理解基于Node实现的“拉链法”。
Java中数据存储方式最底层的两种结构,一种是数组,另一种就是链表,数组的特点:连续空间,寻址迅速,但是在刪除或者添加元素的时候需要有较大幅度的移动,所以查询速度快,增刪较慢。而链表正好相反,由于空间不连续,寻址困难,增刪元素只需修改指針,所以查询速度慢、增刪快。有沒有一种数组结构來综合一下数组和链表,以便发挥它们各自的优势?答案是肯定的!就是:哈希表。哈希表具有较快(常量级)的查询速度,及相对较快的增刪速度,所以很适合在海量数据的环境中使用。一般实现哈希表的方法采用“拉链法”,我們可以理解为“链表的数组”,如下图:
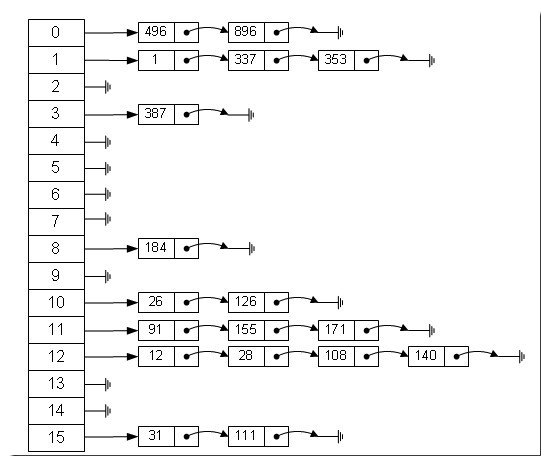
图中,我们可以发现哈希表是由数组+链表組成的,一个长度为16的数组中,每個元素存储的是一个链表的头结点。那么这些元素是按照什么样的规则存储到数组中呢?
一般情況是通过hash(key)获得,也就是元素的key的哈希值。如果hash(key)值相等,则都存入该hash值所对应的链表中。它的內部其实是用一個Node数组來实现。
所以每个数组元素代表一个链表,其中的共同点就是hash(key)相等。
下面我们来了解下链表的基本元素Node。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
// 指向下一个节点
Node<K,V> next;
//构造函数。
// 输入参数包括"哈希值(hash)", "键(key)", "值(value)", "下一节点(next)"
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
// 判断两个Node是否相等
// 若两个Node的“key”和“value”都相等,则返回true。
// 否则,返回false
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
再此结构下,实现了集合的增删改查功能,由于本篇的篇幅有限,这里就不具体介绍其源码实现了。
HashMap遍历方式
1.遍历HashMap的键值对
第一步:根据entrySet()获取HashMap的“键值对”的Set集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
2.遍历HashMap的键
第一步:根据keySet()获取HashMap的“键”的Set集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
3.遍历HashMap的值
第一步:根据value()获取HashMap的“值”的集合。
第二步:通过Iterator迭代器遍历“第一步”得到的集合。
LinkedHashMap实现类
HashSet有一个LinkedHashSet子类,HashMap也有一个LinkedHashMap子类;LinkedHashMap使用双向链表来维护key-value对的次序。
LinkedHashMap需要维护元素的插入顺序,因此性能略低于HashMap的性能;但是因为它以链表来维护内部顺序,所以在迭代访问Map里的全部元素时有较好的性能。迭代输出LinkedHashMap的元素时,将会按照添加key-value对的顺序输出。
本质上来讲,LinkedHashMap=散列表+循环双向链表